Word to vector, main idea
Word embeddings are vectorized, digital representation of words. Word2Vec exists of two types: CBOW and Skip gram, about it later. The main idea of word2vec is that these word embeddings can be used to perform conduct arithmetical operations such as summation and difference, for example:
'king' + ('lion' - 'lioness') ~= 'queen'
Furthermore, the most similar words localize near in embedding space, than less similar words. Thus, you may find most similar words using different measures of distance like cosine or L2 distance.
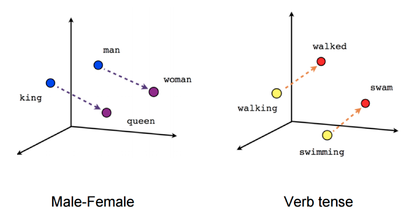
Figure A. Words in embedding space.
Before understand word2vec architectures types, need to know what is target and context.
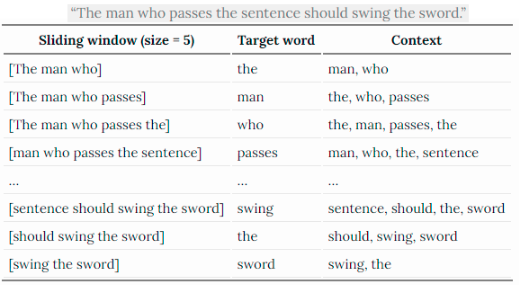
Figure B. Context and target.
Context this is near words to target word, nearness defined by window size - how many words (in left and right) are located from central(or target) word. Great visualization by lil’log on image B.
Types
There are two types of word2vec architecture:
- Skip gram, main idea of this architecture in prediction context by target, or other words, predict near words by the central word. Input of this model is OHE vector with target word, output - vector with probabilities of context words.
- CBOW, main idea in prediction target by context words. The input of this model is OHE vectors with each one is of context word. Output - vector with target word probabilities.
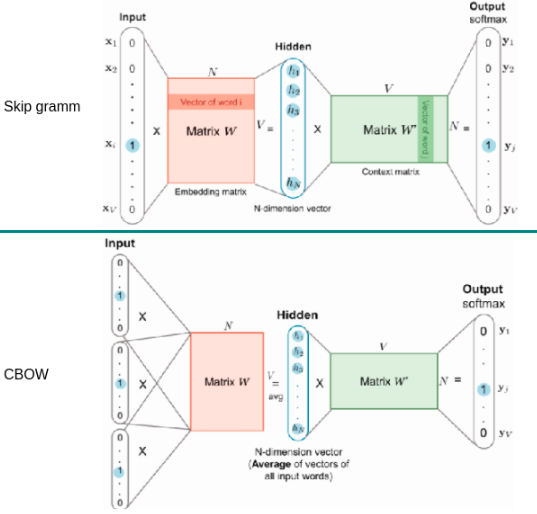
Figure C. Skip gram and CBOW architectures.
Visualization on C figure, result made word embeddings extracted from embedding matrix (weights of the first layer, matrix W). Word2Vec has many variations of loss functions, more detailed in [2].
Links