LSTM
LSTM or long short term memory is a block which can extract information from elements of sequence.
For example a sequence is film frames, elements of sequence are frames, we need to predict character behavior, if we will predict behavior only by one frame predict will “character is stand” but although in reality target is “character dancing”, that conclusion may make LSTM nets, which see all elements or frames.
LSTM return short memory (hidden state) and long memory (cell state).
In context of film, the hidden state for a specific element of sequence is character behavior for a specific frame. Cell state is information about part of film, which characters, what did characters in older frames of the film, this is more “global” info.

Figure A. LSTM cell and(bellow) LSTM layer in the context of sequence.
LSTM consists of 3 parts:
- Forget gate, need to forget older information from long memory(cell state) depending on new sequence element. Irrelevant information about actions in beginning of film (or long memory) unlikely to be actual in the end of movie, need forget old information.
- Input gate, used to add new information in long memory(cell state), update old cell state with a new sequence element. On half of movie appears new character B, need add new info about a new person in a long memory, update cell state.
- Output gate, extract new hidden state(short memory) using long memory or cell state. By new frame of movie character A is stand, but by previous few frames (or short memory) A dance and by long memory person A likes to dance, conclusion - character A dancing.

Figure B. Math part of LSTM. Yellow blocks are parts with parameters, red blocks are functions.
LSTM is not a “many cell” structure, all operations with sequence conducts with one cell on loop wrapper (for this reason LSTM is slow.). For example with PyTorch, LSTM and LSTMCell top and bottom code constructions on image C is equal.

Figure C. Difference between LSTM and LSTMCell in PyTorch.
In the case of BILstm, that layer returns the output for the reverse input sequence case.

Figure D. Bidirectional LSTM, outputs for original and reversed input sequence is concatenate.
Seq2Seq
Seq2Seq is a model which allows translation sequences in sequences, machine translation is a typical task which solves seq2seq model. Seq2Seq consists of two parts: encoder (task of this part in generate context vector by input sequence) and decoder (generate new sequence by context vector from encoder).
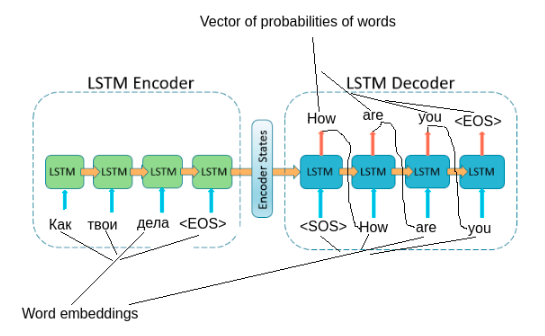
Figure E. Seq2Seq on examples of machine translation.
On image E example of seq2seq model for machine translate, instead LSTM may be used other reccurent layers (such as GRU and others) Input of encoder is a sentence or sequence of words, the element of sequence - word embedding. Output of encoder is the context vector of the sentence. The task of decoder is to generate current word by previous word(or tag), hidden state and by context vector, tags EOS and SOS is mean end and start of sentence.
In PyTorch tutorial when training seq2seq in task of machine translating, used teacher forcing technique with which in decoder pass previous true embedding when predicting current word, instead previous predicted embedding. This trick make training more faster.
Links